Scrapy入门
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序。
其最初是为了页面抓取所设计的,也可以应用在获取API所返回的数据或者通用的网络爬虫。
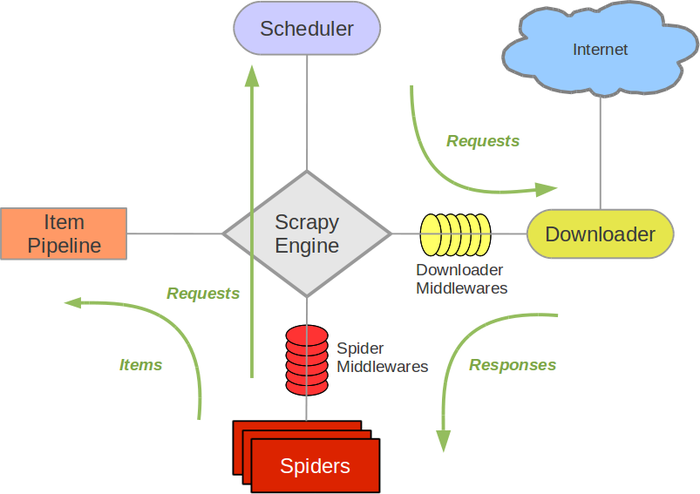
架构概览
Scrapy Engine
引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。详细内容查看下面的数据流部分。
此组件相当于爬虫的”大脑”,是整个爬虫的调度中心。
Scheduler 调度器
调度器从引擎接收request并将他们入队,以便之后引擎请求他们时提供给引擎。
初始的爬取URL和后续在页面中获取的待爬取的URL将放入调度器中,等待爬取。同时调度器会自动去除重复的URL(如果特定的URL不需要去重也可以通过设置实现,如post请求的URL)
Downloader 下载器
下载器负责获取页面数据并提供给引擎,而后提供给spider。
Spiders
Spider是Scrapy用户编写用于分析response并提取item或额外跟进的URL的类。每个spider负责处理一个特定网站。
Item Pipeline
Item Popeline负责处理被spider提取出来的item。典型的处理有清理、验证及持久化。
当页面被爬虫解析所需的数据存入Item后,将被放送到项目管道(Pipeline),经过几个特定的次序处理数据,最后存入本地文件或存入数据库。
Downloader middlewares 下载器中间件
下载器中间件是在引擎及下载器之间的特定钩子,处理Downloader传递给引擎的response。其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
通过设置下载器中间件可以实现爬虫自动更换user-agent、IP等功能。
Spider中间件(Spider middlewares)
Spider中间件是在引擎及Spider之间的特定钩子,处理spider的输入和输出。其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
Data flow 数据流
- 引擎打开一个网站,找到处理该网站的Spider并向该spider请求第一个要爬取的URL。
- 引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)以Request调度。
- 引擎向调度器请求下一个要爬取的URL
- 调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件转发给下载器。
- 一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回response方向)发送给引擎。
- 引擎从下载器中接收到Response并通过Spider中间件发送给Spider处理。
- Spider处理Response并返回爬取到的Item及新的Request给引擎。
- 引擎将(Spider返回的)爬取到的Item给Item Pipline,将(Spider返回的)Request给调度器。
- (从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
安装指南
Scrapy最新版本支持Python2.7,Python3.3+。通过pip安装:
1 | pip install Scrapy # python -m pip install Scrapy |
Scrapy入门
新建一个Scrapy项目。
1 | scrapy startproject tutorial |
该命令将创建包含下列内容__tutorial__目录:
1 | tutorial/ |
Spider
Spiders是你定义的类,它们被用于爬取网站的信息。它们必须继承于scrapy.Spider类。
Spiders类定义了如何跟进页面的链接以及如何分析页面中的内容,提取生成item的方法。
编写第一个Spider,文件名字是quotes_spider.py,放入tutorial/spiders目录下:
1 | import scrapy |
scrapy.Spider子类,需要定义一些属性和方法:
- __name:__Spider名称。用于在Spiders中跟踪Spider,它应该是唯一性的。
- start_requests(): 必须返回一个可迭代的请求对象(你也可以返回一个列表类型的请求对象或一个生成器方法),Spider会调用Request对象开始爬取。
- __parse():__当请求完成时,会调用此方法并将返回内容(response)传入。response是__TextResponse__实例,里面包含页面内容和一些方法。
parse()方法一般用于解析response对象,提取爬取的数据存入字典,它也可以找到新URL加入爬取队列中。
运行spider
在项目跟目录指向:
1 | scrapy crawl quotes |
scrapy.Spider (scrapy.spiders.Spider)
这是最简单的spider,任何个spider都需要继承它。它并不会提供特殊的方法,它只默认提供start_requests()实现。start_requests()会从start_urls读取请求链接发起请求,当请求完成后会自动调用parse方法将返回结果作为参数response传入。
name
定义spider名字,它被用于Scrapy定位spider,所以它必须是唯一的。
如果spider被用于爬取单个网站,一个最常见的做法是以该网站域名来命名spider。例如:mywebsite.com,该spider通常被命名未mywebsite。
allowed_domains
一组可以爬取的域名字符串,如果OffsiteMiddleware开启,不在此列表中的域名不会被爬取。
start_urls
URL列表,如果没有特殊URL被定义,spider会先从这个列表取URL进行爬取,后续的URL会从爬取的页面中获取到。
__custom_settings
定义当前spider配置,它会覆盖项目配置。它必须被定义未类属性,因为它会在实例化前使用到。
start_requests()
整个方法必须返回一个可迭代对象。该对象包含spider用于爬取的第一个Request。
当spider启动爬取并且未制定URL时,该方法被调用。
默认会对start\_urlsurl一次执行Request(url,dont\_filter=true)
如果您想要修改最初爬取某个网站的Request对象,您可以重写(override)该方法。 例如,如果您需要在启动时以POST登录某个网站,你可以这么写:
1 | class MySpider(scrapy.Spider): |
Spider 参数
Spiders能够接收参数并编辑它们。有些用户会同过参数定义spider起始URL或者限制爬虫爬取页面的区域。
它们也可以被用于配置spider任何功能。
1 | scrapy crawl myspider -a category=electronics |
Spider中__init__方法接收传入的参数:
1 | import scrapy |
__init__ 方法默认的会将接收到的参数赋值个spider一个同名属性。所以上面的例子可以改写为:
1 | import scrapy |
通用Spiders
Scrapy附带一些有用的通用蜘蛛,你可以继承它们。它们为一些常见的案例提供便捷的功能。
例如遵循特定的规则爬取站点链接,解析XML/CSV。
CrawSpider (class scrapy.spiders.CrawlSpider)
爬取一般网站用的spider。定义一些规则来提供跟进link的方便机制。也许该spider不完全适用于你的站点,可以根据自己的需求修改部分方法。当然你也可以实现自己的spider。
rules
rules是个包含一个或多个Rule对象的列表。每个Rule为爬虫定义爬取网站的行为规则。如果有多个rule匹配到同一个链接,第一个匹配到的规则会使用它。
这个spider暴露了一个可以覆盖的方法:
parse_start_url(response)
当__start_urls__链接有返回时,这个方法会被调用。这个方法能够解析返回值并且必须返回一个item对象或一个Request对象或一个可迭代的包含两者的对象。
爬取规则Crawling rulesclass scrapy.spiders.Rule(link_extractor, callback=None, cb_kwargs=None, follow=None, process_links=None, process_request=None)
link_extractor一个 Link Extractor对象,它定义了如何从页面从提取链接。callback是个可执行方法或一个字符串(在spider定义了的方法)。它会在提取到符合要求的链接时触发。这个方法接收一个response作为第一个参数,它必须返回一个包含item或Request对象的列表。(注意:这个方法名称不能是__parse__)cb_kwargs包含传递给回调函数的参数(keyword argument)的字典。follow一个布尔值。说明从返回中提取的符合规则的链接是否跟进。如果callback值是None则它的值默认是True,否则是Falseprocess_links是个可执行方法或一个字符串(在spider定义了的方法)。每当link\_extractor的一个链接获取到reponse它就会被调用。它一般用于过滤。process_request是个可执行方法或一个字符串(在spider定义了的方法)。每当link\_extractor一个链接发起request时它就会被调用。它必须返回一个request对象或None
1 | import scrapy |
XMLFeedSpider
XMLFeedSpider被设计为通过迭代确定的节点来解析XML源。迭代器能够选择为__iternodes__,xml,html__。
从性能上考虑推荐使用__iternodes__,因为__xml,__html__迭代器读取整个DOM用来解析。但是,不过使用__html__作为迭代器能有效应对错误的XML。
你必须设置一下属性确定使用的迭代器和标签名。
iterator
使用的迭代器名字,有三个选项:
- iternodes: 基于正则表达很快的一个迭代器。
- html: 基于__Selector__的正则表达式。需要注意的是,它需要将DOM全部加载到内存解析,在大数据源情况下可能会有问题。
- xml: 基于__Selector__的正则表达式。需要注意的是,它需要将DOM全部加载到内存解析,在大数据源情况下可能会有问题。
itertag
定义需要迭代的节点名称。
1 | itertag = 'product' |
namespaces ?
有元组__(prefix, url)__组成的列表,它了定义这个文档可用的名称空间,这些元组将被spider处理。__prefix__和__uri__会自动被注册名称空间通过使用__register_namespace()__方法。
在__itertag__属性上指定节点的名称空间。
1 | class YourSpider(XMLFeedSpider): |
除了这些新的属性,spider还提供了下面这些可以覆盖的方法。
adapt_response(response)
这个方法在spider分析response前被调用。你可以在这个方法编辑response主体在spider解析它之前。这个方法接收response并放回response。
parse_node(response, selector)
当迭代的节点和__itertag__相匹配时这个方法会被触发。每个节点会接收到__response__和__Selector__作为参数。这个方法是强制被重写的,否则spider不会正常工作。这个方法必须返回一个__item__对象或者一个__Request__对象,或者一个包含这两者的可迭代对象。
process_results(response, results)
当spider返回一个结果(item或者request)时,这个方法会被调用。它的目的是返回的结果在被传给框架核心前做最后的请求处理。例如设置item ID。它接收一个结果列表和对应的响应。它必须返回一个结果(Item or Request)列表。
XMLFeedSpider 例子:
1 | from scrapy.spiders import XMLFeedSpider |
Selectors
在爬取页面时,做的最多的任务就是从页面中提取需要的数据。完成这个任务最常用的库有:__BeautifulSoup__,__lxml__。
Scrapy有自己的提取数据的机制。它被成为选择器(selectors)。通过指定的__Xpath__或__CSS__表达式选取文档中符合要求的部分。
Scrapy选择器基于lxml库,它非常简单和快速。
使用选择器
Scrapy选择器时__Selector__类的实例,通过传递一个text或__TextResponse__对象完成构造。它会根据输入内容自动选择最佳的解析规则(XML vs HTML)。
1 | from scrapy.selector import Selector |
为了方便,__response__对象提供了选择器 __.selector__属性。这是个完全可靠的便捷方式。
1 | response.selector.xpath('//span.text()').extract() |
例子
通过scrapy shell获取response。
1 | scrapy shell http://doc.scrapy.org/en/latest/_static/selectors-sample1.html |
获取页面标题:
1 | response.selector.xpath('//title/text()') |
.xpath()和.css()方法返回的是个SelectorList实例。
提取文本数据需要调用.extract()方法。
1 | response.xpath('//title/text()').extract() # [u'Example website'] |
如果你想获取匹配元素中第一个元素文本可以使用.extract_first()
1 | response.xpath('//div[@id="images"]/a/text()').extract_first() |
如果没有匹配元素存在会放回None
1 | response.xpath('//div[@id="not-exists"]/text()').extract_first() is None #True |
可以给不存在的元素设置一个默认返回值。
1 | response.xpath('//div[@id="not-exists"]/text()').extract_first(default='not-found') |
选择器有个re()方法支持用正则表达式提取数据。re()方法返回的是个unicode字符串列表。
Item
Item是保存爬取到的数据的容器;其使用方法和python字典类似。Scrapy中可以直接使用dict,但是Item提供了额外保护机制来避免拼写错误导致的未定义字段错误。Item也可以于Item Loaders一起使用,item Loaders可以快速将数据填充进Item。
根据可能获取到的数据对item进行建模。
1 | import scrapy |
Item Fields
Field对象用于指定每个字段的元数据。例如,上面的例子中last_updated所示字段的序列化函数。
你可以给字段指定任何类型的元数据。Field对象接收的值没有限制,因为这个原因,没有可用的元数据key的参考列表。Field对象定义的key可以被用在不同的组件中,只要组件知道它们用途。
创建一个Item
1 | product = Product(name = 'PC',price = 1000) |
获取字段值
1 | product['name'] # PC |
获取所有的值
1 | product.keys() |
其它任务
1 | product2 = Product(product) # 赋值item |
Item Loaders
Loader提供一个方便的机制用于填充scraped Items。尽管Items可以利用类似于dicAPI填充数据,但Loader提供更方便的API用于在爬取过程中填充。
换句话说,__Items__提供装爬取数据的容器而item Loader提供填充容器的机制。
Item Loader提供灵活,有效,简单的机制用于扩展和重写不用的字段解析规则,无论是spider还是源格式(HTML,X,ML)。避免了后期噩梦般的维护。
使用Item Loaders
要使用一个Item Loader,你必须首先实例化它。你可以像字典对象一样实例化也可以没有对象,这样情况下Item Loader构造时自动使用一个Item实例化,这个Item被赋予ItemLoader.default_item_class属性。
然后,你就可以向Item Loader里面收集数据了,通常的做法是使用Selectors。你给一个字段添加多个值。Item Loader会使用合适的处理函数加载这些值。
下面例子,将Item Loader用于Spider,使用了 Product item定义的 Items。
1 | from scrapy.loader import ItemLoader |
上面例子中,通过add_xpath()方法,在页面两个不同的地方将数据收集起来赋给name字段。
//div[@class="product_name"]//div[@class="product_title"]
后面使用add_css()或add_value()方法填充stock字段和last_updated字段。
最后,当所有数据被收集起来后,调用ItemLoader.load_item()方法,返回填充好的Item。输入和输出处理器
一个Item Loader在每个字段中包含一个输入处理器和一个输出处理器。输入处理器处理通过
add_xpath(),add_css(),add_value()提取的数据。输入处理器的结果会被ItemLoader收集并保存。在收集到所有数据后调用ItemLoader.load_item()方法来填充并获得填充后的Item对象。输出处理器调用会使用之前收集到的数据,它处理的完后的结果会被分配到item中。
让我们看一个例子来说明如何输入和输出处理器被一个特定的字段调用:1
2
3
4
5
6l = ItemLoader(Product(), some_selector)
l.add_xpath('name', xpath1) # (1)
l.add_xpath('name', xpath2) # (2)
l.add_css('name', css) # (3)
l.add_value('name', 'test') # (4)
return l.load_item() #看看发生了什么:
数据从
xpath1提取出来,通过name字段的输入处理器。输入处理器的结果会被Item Loader收集和保存起来(并没有分配给 item)数据从
xpath2提取出来,通过和(1)一样的输入处理器。输入处理器的结果会被附加到(1)的结果上(如果有)。这步和上面类似,除了数据是通过
CSS selector提取。通过和(1),(2)一样的输入处理器。输入处理器的结果会被附加到(1),(2)上(如果有)。这步和上面类似,除了数据值是直接被指定的,代替了从
XPath表达式和CSS选择器提取。这值依然被传递给输入处理器。这个例子中,值不是可迭代对象,它会被转换为可迭代对象在传给输入器之前,因为输入器只接收可迭代的对象。(1),(2),(3),(4)步收集的数据会传给
name字段的输出处理器。输出处理器的结果会被分配给item的name字段。
只的注意是处理器只是个可调用的对象,它调用需要被解析的数据,返回解析后的值。你可以使用任何函数作为输入和输出处理器。唯一的要求是它们必须接收一个而且只能接收一个可迭代的对象作为参数。
输入和输出处理器必须接收一个可迭代的对象作为它们第一个参数。而它们函数的输出可以是任何值。输入处理器的结果会被插入一个包含有这个字段收集的值的列表中。输出处理器的结果会作为最终的值分配给item。
Scrapy 附带了一些便捷的通用处理器。
声明Item Loader
Item Loader可以像Item一样被定义,使用class语法定义。例子:
1 | from scrapy.loader import ItemLoader |
就如你看到的,输入处理器使用_in后缀定义而输出处理器使用_out后缀语法定义。你也可以使用ItemLoader.default_input_processor和ItemLoader.default_output_processor属性定义。
声明输入和输出处理器
如上小结所示,输入和输出处理器能够在定义Item Loader的class中声明,这是一种很通用的声明处理器的方法。
然而很多地方,你可以在定义Item Field 元数据时,指明使用的输入和输出处理器。例如:
1 | import scrapy |
调用:
1 | from scrapy.loader import ItemLoader |
输入和输出处理器的优先处理顺序是:
- Item Loader字段指明的属性:
field_in和field_out优先级最高。 - 字段元数据(input_processor和output_processor键)
- Item Loader默认:
ItemLoader.default_input_processor()和ItemLoader.default_output_processor()最低。
ItemLoader Objects
class scrapy.loader.ItemLoader([item,selector,response,]**kwargs)
提供需要处理的一个Item,会返回一个新的Item Loader。如果没有提供Item,实例化时会自动使用default_item_class。
当使用__selector__和__response__实例话时,ItemLoader类提供了方便的机制从页面中使用选择器提取数据。
参数:
- item — 需要处理的Item 实例
- selector — 提取数据的选择器,可以使用
add_xpath(),add_css(),replace_xpath()方法。 - response — response会使用
default_selector_class作为选择器如果在构造时没有传递selector参数。
实例话后的ItemLoader拥有下面这些方法:
get_value(value, *processors,**kwargs)
处理value通过给定处理器和关键字参数。
有效的关键字:
- Parameters: re(字符串或正则表达式) 一个正则表达式用于
extarct_regex()方法从value中提取数据,在交给处理器之前。from scrapy.loader.processors import TakeFirst
loader.get_value(u'name: foo', TakeFirst(), unicode.upper, re='name: (.+)')add_value(field_name,value,*processors, **kwargs)
将value添加到给定字段上。
这个值首先将经过给get_value()如果提供了processors和kwargs,然后通过字段的输入处理器。输入处理器的结果会附加上这个字段已经收集到的数据上。
1 | loader.add_value('name', u'Color TV') |
replace_value(field_name, value, *processors, **kwargs)
类似于add_value()但是用value替换已经收集到的数据。
get_xpath(xpath, *processors, **kwargs)
类似ItemLoader.get_value()但是接收一个XPaht 替换value,该值用于从与此关联的选择器中提取unicode字符串列表ItemLoader。
- Parameters:
- xpath(str) - 从XPath提取数据
- re(字符串或正则表达式)- 这个正则表达式用于提取数据从选择的XPath 区域。
```# HTML snippet: <p class="product-name">Color TV</p>```
```loader.get\_xpath('//p[@class="product-name"]')```
```# HTML snippet: <p id="price">the price is $1200</p>```
```loader.get\_xpath('//p[@id="price"]', TakeFirst(), re='the price is (.*)')```
add_xpath(field_name,xpath, *processors, **kwargs)
类似于ItemLoader.add_value()但是使用XPath代替value,该值用于从与此关联的选择器中提取unicode字符串列表ItemLoader。
1 | # HTML snippet: <p class="product-name">Color TV</p> |
replace_xpah(field_name, value, *processors, **kwargs)
类似于add_xpath()。
Item Pipeline
当item被spider收集后,它会送到Item Pipeline经过几个连续的组件处理。
每个Item pipeline组件是个实现了一个简单方法Python 类。它接收一个item,对它做些操作,已决定item是继续传给pipeline或者销毁不再做处理。
典型的item pipelines有:
- 清理HTML数据
- 确认爬取的数据
- 检测是否重复
- 将item存储到数据库
写个item pipeline
每个item pipeline 组件是个Python 类,它必须实现下面这个方法:
process_item(self,item,spider)
item pipeline组件会调用这个方法。这方法必须返回一个dict数据或者返回一个Item对象。或一个Twisted Deferred,或一个DropItem异常。丢弃的items不会在后面的pipeline处理。
参数:
- item — 被爬取的item
- spider — 爬取item的spider
可以选择实现下面这些方法:
open_spider(self,spider)
当spider被打开时这个方法会被调用。
参数:
- spider — 被打开的spider
close_spider(self, spider)
当spider被关闭时调用。
参数:
- spider — 被关闭的spider
from_crawler(cls, crawler)
如果它有,这应该是个类方法当Crawler实现一个pipeline时调用。
它必须返回一个实现了的pipleline。Crawler对象提供了 Scrapy 所有核心组件访问,例如设置和信号。这是pipeline访问并挂载功能到Scrapy唯一的方式。
参数:
- crawler — crawler给pipeline使用
去掉没有价格的item
1 | from scrapy.exceptions import DropItem |
上面的pipeline调整itemprice属性如果包含price_excludes_vat属性,然后抛弃没有price属性的items。
将items写入JSON文件
1 | import json |
上面的pipeline将所有spiders的items存入到一个item.jl文件中。每一行包含一条序列化后的item。
__注意:__JsonWriterPipeline目的只是为了介绍怎样写入item pipeline。如果你真的想将所有 items 存储到JSON file你需要使用Feed exports。
写入 MongoDB
1 | import pymongo |
上面的例子会将items写入MongoDB通过pymongo。MongoDB的地址和数据库名称是由Scrapy settings指定。MongoDB 集合名称就是 item class。
上面的例子只是为了指明怎么使用from_crawler()方法和怎样清除资源。
拿到item的快照
1 | import scrapy |
上面例子示范了process_item()方法如何返回一个延迟(Deferred)方法。例子使用了Splash渲染item url的快照。Pipeline确保请求在本地运行Splash实例。当请求下载结束后,延迟方法会被触发。它保存了item到一个文件中,文件名就是item。
去重
1 | from scrapy.exceptions import DropItem |
上面的例子过滤重复的item,抛弃那些一ing处理过的items。
激活Item Pipeline 组件
激活Item Pipeline组件你必须添加 class到Item_PIPELINES配置中。例如下:
1 | ITEM_PIPELINES = { |
分配给每个类的整型值,确定了他们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内
Settings
Scrapy settings 允许你自己定义所有Scrapy 组件的行为。包括核心库,扩展,pipeline和spider。
这些基础结构的settings为全局提供了key-value形式的命名空间,代码可以用拉取配置的值。这些settting能通过不同的机制填充。
指定设定
当使用Scrapy时,你需要指定你所使用的setting。这可以通过使用环境变量:SCRAPY_SETTRINGS_MODULE来完成。SCRAPY_SETTRINGS_MODULE必须以Python路径语法编写,例如:myproject.settings。
填写settings
填写Settings有不同的机制,每个机制有其优先顺序。下面列表以降序的顺序给出了优先级:
- 命令行选项(Command line Options)(最高优先级)
- 每个spider的设定
- 项目设定模块(Project settings module)
- 命令默认设定模块(Default settings per-command)
- 全局默认设定(Default global settings) (最低优先级)
命令行选项(Command line options)
命令行传入的参数具有最高的优先级。 您可以使用command line 选项 -s (或 –set) 来覆盖一个(或更多)选项。
1 | scrapy crawl myspider -s LOG_FILE=scrapy.log |
spider内指定Settings
spider可以设定它们自己settings,它会覆盖项目的settings。它们可以通过scrapy.spiders.Spider.custom_settings属性设定。
项目settings
项目设定模块是你Scrapy项目标准配置文件。这个是设定你大多数settings的地方。标准的Scrapy项目,这个方式你需要创建一个settings.py文件在你目录中。
命令默认settings
每个Scrapy tool拥有自己的默认设置,并覆盖全局的默认设置。这个自定义的通用设置指定在通用class的default_settings属性上。
默认全局settings
全局默认设定存储在 scrapy.settings.default_settings 模块, 并在 内置设定参考手册 部分有所记录。
访问settings
在spider中,settings可用通过self.settings
1 | class MySpider(scrapy.Spider): |
__注意:__这个settings属性是在spider初始化后,Spider类中设置的。如果你想使用settings在初始化之前(例如:你的spider__init()__方法),你必须重写from\_crawler()方法。
settings可以在Crawler的scrapy.crawler.Crawler.settings属性中接收到。它可以在扩展,中间件,item pipeline的from_crawler方法中取到。
1 | class MyExtension(object): |
命令行工具
Scrapy是通过scrapy命令行控制的。
Scrapy tool 针对不同的目的提供了多个命令,每个命令支持不同的参数和选项。
调整设置
Scrapy将会在以下路径中寻找记录了配置参数的 scrapy.cfg 文件, 该文件以ini的方式记录:
/etc/scrapy.cfg或c:\scrapy\scrapy.cfg(系统层面),~/.config/scrapy.cfg($XDG_CONFIG_HOME) 及~/.scrapy.cfg ($HOME)作为全局(用户层面)设置, 以及- 在scrapy项目根路径下的 scrapy.cfg (参考之后的章节).
从这些文件中读取到的设置按照以下的顺序合并: 用户定义的值具有比系统级别的默认值更高的优先级, 而项目定义的设置则会覆盖其他.默认Scrapy项目结构
1
2
3
4
5
6
7
8
9
10
11scrapy.cfg
myproject/
__init__.py
items.py
pipelines.py
settings.py
spiders/
__init__.py
spider1.py
spider2.py
...scrapy.cfg存放的目录被认为是 项目的根目录 。该文件中包含python模块名的字段定义了项目的设置。1
2[settings]
default = myproject.settings创建项目
一般来说scrapy工具第一件事是创建Scrapy项目:1
scrapy startproject myproject
创建spider
创建spider快捷方法1
2# scrapy genspider [-t template] <name> <domain>
scrapy genspider myspider mydomain.com调用 spider
1
2#scrapy crawl <spider>
scrapy crawl myspider列出 spider
1
2scrapy list
# myspider通过链接加载页面
使用Scrapy下载器(downloader)下载给定的URL,并将获取到的内容送到标准输出。1
2#scrapy fetch <url>
scrapy fetch --nolog http://www.example.com/some/page.htmlspider方式展示页面
在浏览器中打开给定的URL,并以Scrapy spider获取到的形式展现。 有些时候spider获取到的页面和普通用户看到的并不相同。 因此该命令可以用来检查spider所获取到的页面,并确认这是您所期望的。1
2#scrapy view <url>
scrapy view http://www.example.com/some/page.html解析链接
获取给定的URL并使用相应的spider分析处理。如果您提供 –callback 选项,则使用spider的该方法处理,否则使用 parse 。1
scrapy parse <url> [options]
- –spider=SPIDER: 跳过自动检测spider并强制使用特定的spider
- –a NAME=VALUE: 设置spider的参数(可能被重复)
- –callback or -c: spider中用于解析返回(response)的回调函数
- –pipelines: 在pipeline中处理item
- –rules or -r: 使用 CrawlSpider 规则来发现用来解析返回(response)的回调函数
- –noitems: 不显示爬取到的item
- –nolinks: 不显示提取到的链接
- –nocolour: 避免使用pygments对输出着色
- –depth or -d: 指定跟进链接请求的层次数(默认: 1)
- –verbose or -v: 显示每个请求的详细信息
作者: Fynn
链接: https://fynn90.github.io/2017/11/19/scrapy%E5%85%A5%E9%97%A8/
本文采用知识共享署名-非商业性使用 4.0 国际许可协议进行许可